|
I am an AI Engineer at NetEase Games. Previously, I obtained my Ph.D. at the University at Buffalo, advised by Prof. Junsong Yuan. Prior to that, I completed my Master degree from the University of Southern California, and my Bachelor degree from Lanzhou University. Rooted in computer vision and machine learning, my current research interests lie in human-centric motion perception/analysis/generation, character animation, animatable avatar, 6-DoF object pose estimation, and 3D reconstruction. Email | CV | Google Scholar | GitHub | LinkedIn |

|
|
|
|
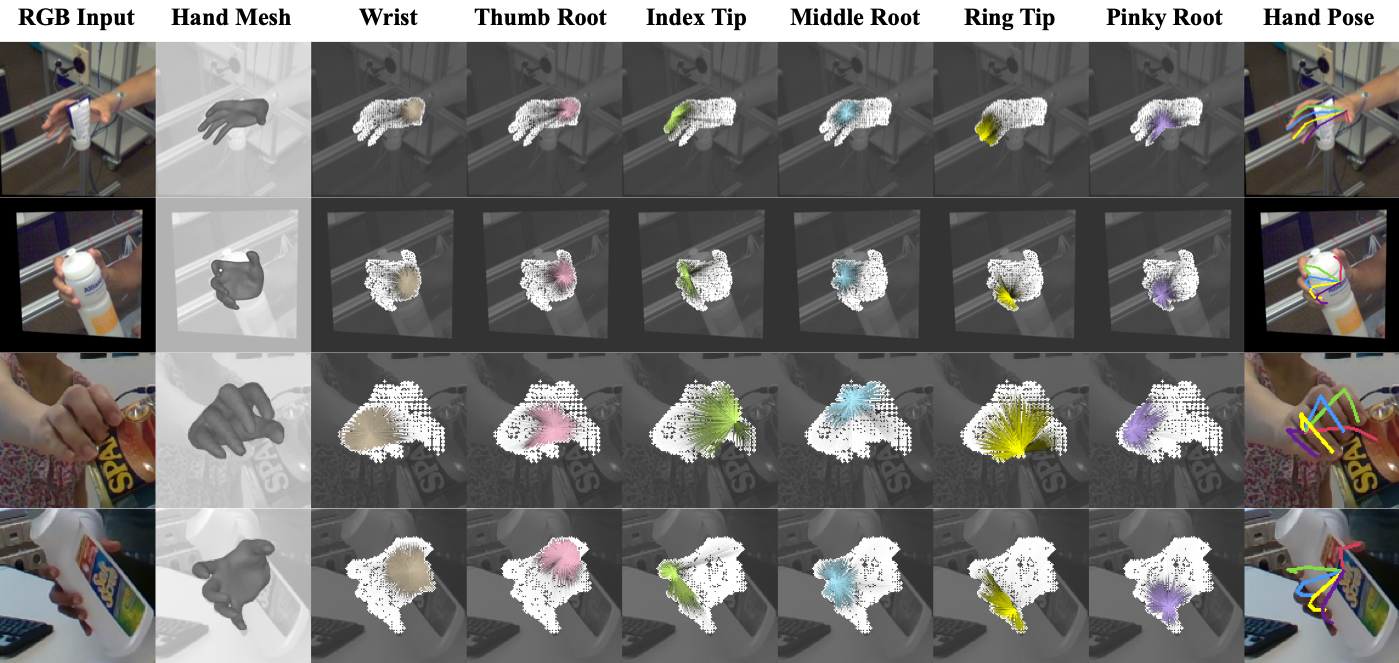
Lin Huang, Chung-Ching Lin, Kevin Lin, Lin Liang, Lijuan Wang, Junsong Yuan, Zicheng Liu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2023, Vancouver |
|
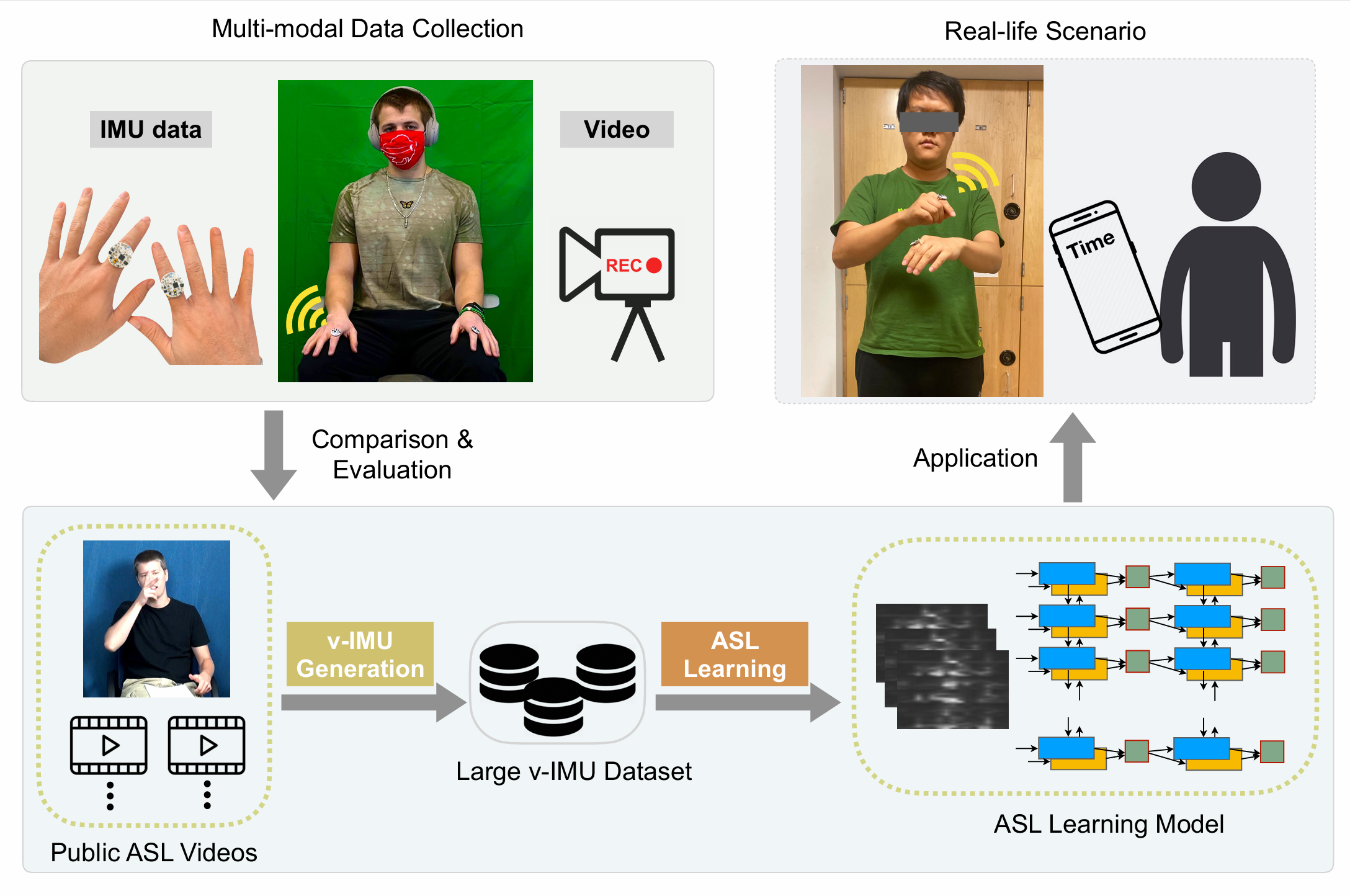
Jiyang Li, Lin Huang, Siddharth Shah, Sean J Jones, Yincheng Jin, Dingran Wang, Adam Russell, Seokmin Choi, Yang Gao, Junsong Yuan, Zhanpeng Jin ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT) 2023 |

|
Lin Huang, Tomas Hodan, Lingni Ma, Linguang Zhang, Luan Tran, Christopher Twigg, Po-Chen Wu, Junsong Yuan, Cem Keskin, Robert Wang European Conference on Computer Vision (ECCV) 2022, Tel-Aviv |
|
Lin Huang*, Boshen Zhang*, Zhilin Guo*, Yang Xiao, Zhiguo Cao, Junsong Yuan Virtual Reality and Intelligent Hardware (VRIH) 2021 |
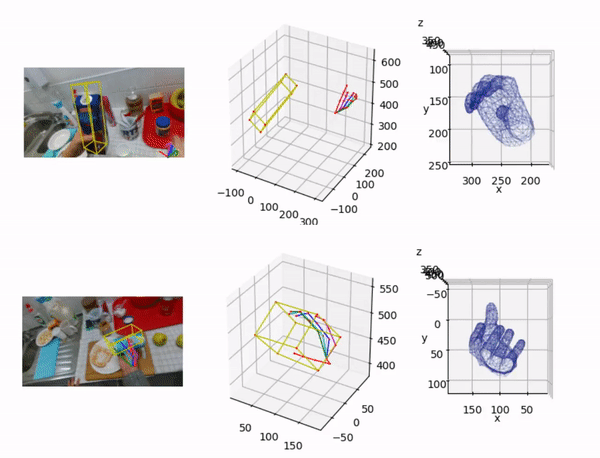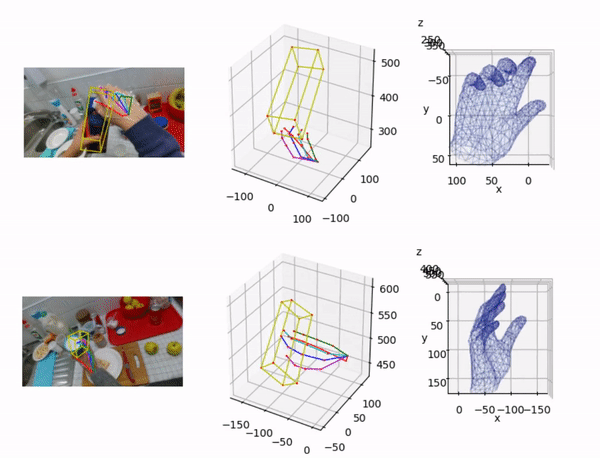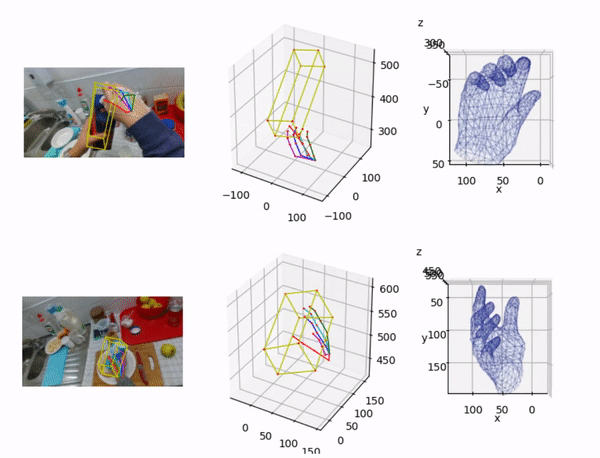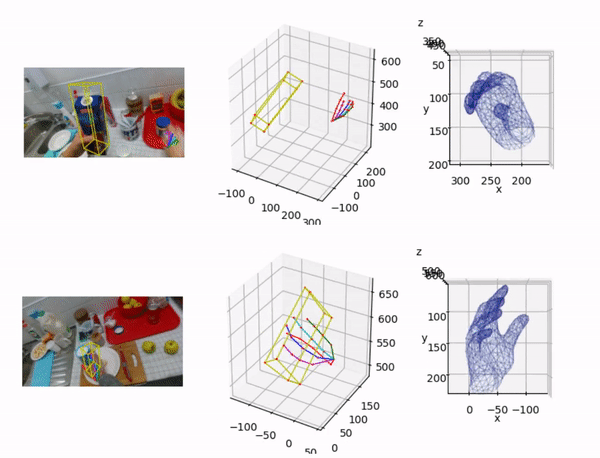
|
Lin Huang, Jianchao Tan, Jingjing Meng, Ji Liu, Junsong Yuan ACM International Conference on Multimedia (ACM MM) 2020, Seattle |
|
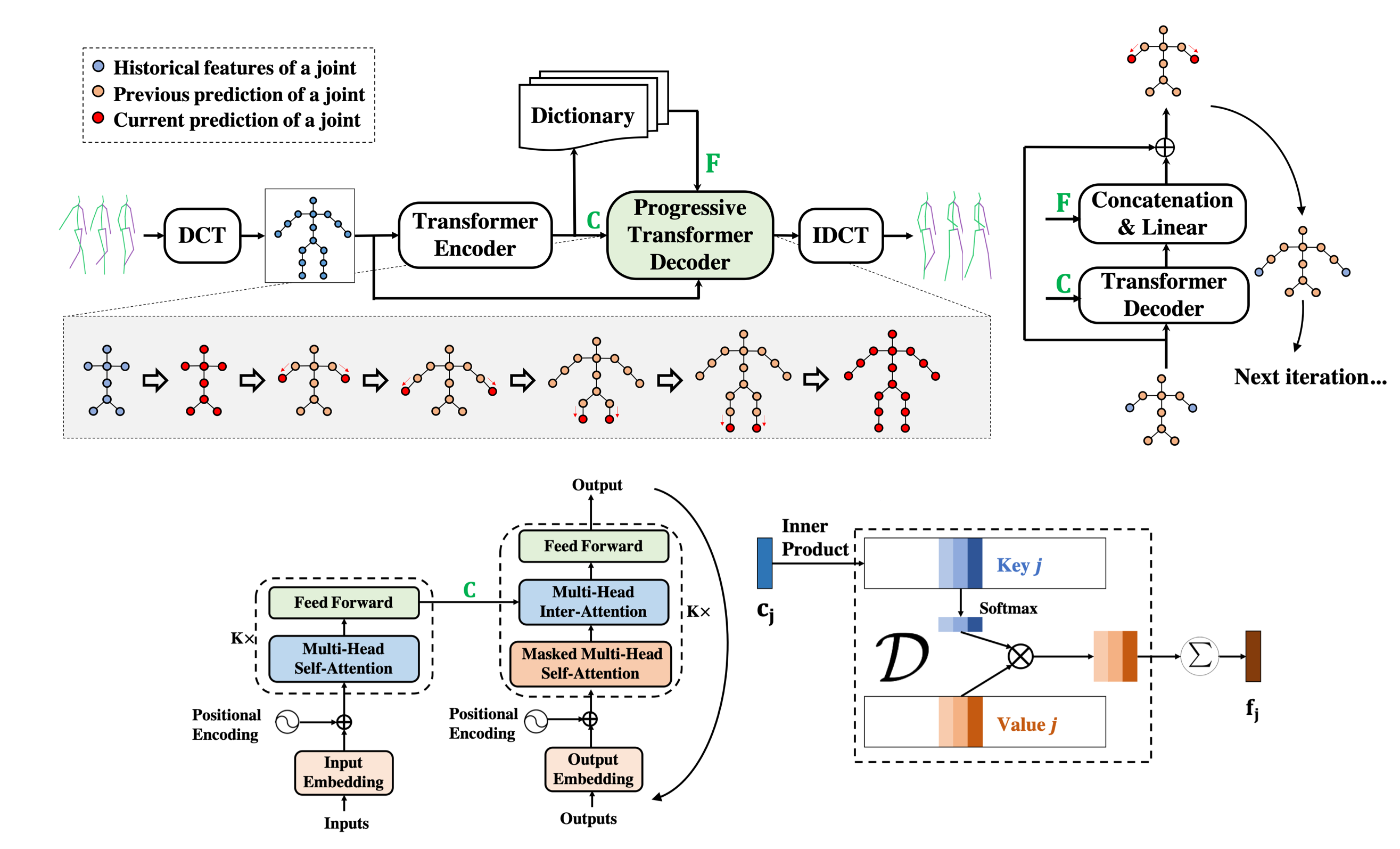
Lin Huang, Jianchao Tan, Ji Liu, Junsong Yuan European Conference on Computer Vision (ECCV) 2020, Glasgow |
|
Yujun Cai, Lin Huang, Yiwei Wang, Tat-Jen Cham, Jianfei Cai, Junsong Yuan, Jun Liu, Xu Yang, Yiheng Zhu, Xiaohui Shen, Ding Liu, Jing Liu, Nadia Magnenat Thalmann European Conference on Computer Vision (ECCV) 2020, Glasgow |

|
Lin Huang, Pranav Sankhe, Yiheng Li
[CODE]
|
|
AI Engineer: NetEase Information Technology Corp., Irvine, CA, USA Oct. 2023 - Present Research Intern: Microsoft Corporation, Azure AI, Redmond, WA, USA Supervisor: Dr. Chung-Ching Lin, Dr. Kevin Lin, Dr. Lin Liang, Dr. Lijuan Wang, Dr. Zicheng Liu May. 2022 - Aug. 2022 Part-Time Student Researcher: Meta (formerly Facebook, Inc.), Reality Labs, Redmond, WA, USA Supervisor: Dr. Tomas Hodan Dec. 2021 - Apr. 2022 Research Intern: Meta (formerly Facebook, Inc.), Reality Labs, Redmond, WA, USA Supervisor: Dr. Tomas Hodan Aug. 2021 - Dec. 2021 Research Intern: Kwai Inc., Y-tech Lab, Seattle, WA, USA Supervisor: Dr. Jianchao Tan, Dr. Ji Liu May. 2020 - Aug. 2020 |
|
Conference Reviewer: CVPR, ECCV, ICCV, ACM MM, WACV, ICIP, ICPR, WF-IOT Journal Reviewer: TPAMI, TIP, IJCV, TCSVT, TIM, TVCJ, JVCI, MVAP, SPIC, PR |
|
Teaching Assistant: CSE531 Analysis of Algorithms I, UB, Spring 2023 Teaching Assistant: CSE191 Introduction to Discrete Structures, UB, Spring 2021 Teaching Assistant: CSE555 Introduction to Pattern Recognition, UB, Fall 2020 Teaching Assistant: CSE587 Data Intensive Computing, UB, Spring 2020 |
|
Website Template
|